تقنيات حلول الأعمال حلول البيانات هندسة برمجيات يونيو 13, 2025
في عصر يتسارع فيه الذكاء الاصطناعي بوتيرة غير مسبوقة، لم تعد الطرق التقليدية لتخزين البيانات والبحث عنها قادرة على مواكبة التعقيد المتزايد في طبيعة المعلومات. فالنصوص، الصور، والمقاطع الصوتية لم تعد مجرّد بيانات خام، بل أصبحت كيانات غنية بالمعاني، تتطلب أدوات أكثر ذكاء لفهمها وتحليلها.
هنا تبرز الحاجة إلى نوع جديد من قواعد البيانات، لا يعتمد فقط على الصفوف والأعمدة، بل يفهم التشابه في المفاهيم، ويستوعب البُعد الدلالي في البيانات. هذا النوع يُعرف بـ قواعد بيانات المتجهات (Vector Databases).
في هذه التدوينة، سنأخذك في رحلة لفهم هذا المفهوم الثوري:
- ما هي قاعدة بيانات المتجهات؟
- لماذا ظهرت؟
- كيف تختلف عن قواعد البيانات التقليدية؟
- وكيف تدعم تطبيقات الذكاء الاصطناعي والبحث الدلالي اليوم؟
سواء كنت مطوراً ناشئاً، أو مهتماً ببناء روبوت محادثة ذكي، أو تبحث عن أدوات تعزز تجربة البحث في منتجك، فستجد في هذه التدوينة ما يضعك على بداية الطريق، بلغة واضحة، وشرح مبسّط، وأمثلة واقعية.
ما هي قاعدة بيانات المتجهات؟ ولماذا ظهرت؟
عند الحديث عن قواعد البيانات، يتبادر إلى الذهن فوراً جداول مكونة من صفوف وأعمدة، نستخدم معها استعلامات SQL لاسترجاع المعلومات بدقة. لكن ماذا لو أردنا البحث عن صورة “تشبه” صورة معينة؟ أو عن مقطع صوتي “قريب في النبرة والمحتوى” من مقطع آخر؟ أو عن مقال يُعبّر عن فكرة ما، دون أن يحتوي بالضرورة على الكلمات نفسها؟
هنا تفشل قواعد البيانات التقليدية، لأن استعلاماتها تعتمد على التطابق الحرفي لا التشابه المعنوي.
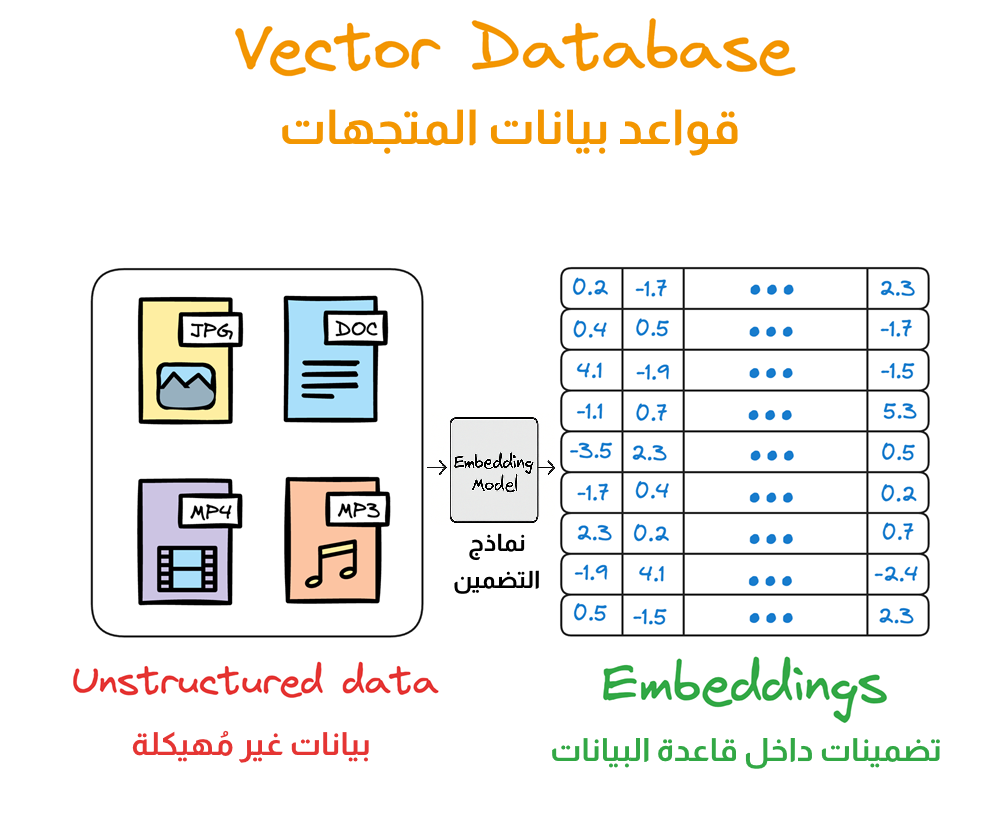
لذلك ظهرت قواعد بيانات المتجهات (Vector Databases)، وهي جيل جديد من قواعد البيانات صُمِّم خصيصًا للتعامل مع البيانات غير المهيكلة (Unstructured Data) مثل النصوص، الصور، الأصوات، والفيديو.
ما يميزها هو قدرتها على تمثيل هذه الأنواع من البيانات كـ متجهات عددية (Vectors)، أي كسلاسل من الأرقام تعكس الخصائص الدلالية الكامنة في تلك البيانات.
على سبيل المثال، لدينا مقالتان مختلفتان في الصياغة لكنهما تتحدثان عن “رؤية السعودية 2030” سيتم تمثيلهما كمتجهين متقاربين جداً وذلك عند تخزينهم في قاعدة البيانات، لأن معناهما متشابه.
هذه القدرة على فهم المعنى، وليس فقط الشكل، تجعل من قواعد بيانات المتجهات أداة أساسية في تطبيقات الذكاء الاصطناعي، مثل:
- أنظمة التوصية الذكية
- محركات البحث الدلالية
- روبوتات المحادثة
- تحليل المحتوى
- التوليد المعزز بالاسترجاع (RAG)
في المحصلة، قاعدة بيانات المتجهات لا تستبدل القاعدة التقليدية، بل تُكملها، خاصة عندما يصبح المعنى أكثر أهمية من الشكل.
ما هو المتجه؟ ولماذا هو مهم؟
لفهم طريقة عمل قواعد بيانات المتجهات، لا بد أولاً أن نتعرف على المفهوم الأساسي الذي تقوم عليه: المتجه (Vector).
المتجه في هذا السياق ليس مجرد رقم أو مصفوفة جامدة، بل هو تمثيل عددي لمعلومة ذات معنى، سواء أكانت نصاً مكتوباً، صورة مرئية، أو مقطعاً صوتياً.
لكن كيف يمكن لمعلومة معقدة مثل مقالة أو صورة أن تتحول إلى سلسلة من الأرقام؟
هنا يأتي دور نماذج التضمين (Embedding Models)، وهي نماذج ذكاء اصطناعي مدربة على مليارات البيانات. تعمل هذه النماذج على تحليل المحتوى واستخلاص خصائصه الدلالية – أي معناه وسياقه – ثم تحويله إلى متجه: سلسلة من القيم الرقمية تمثل هذا المعنى.
كل متجه يتكوّن من مجموعة من الأرقام (مثل: 0.12، 0.85، 0.43…)، بحيث تمثل كل قيمة منها بُعداً معيناً داخل ما يسمى بـ فضاء المتجهات.
📦 ما هو فضاء المتجهات؟
في الأدبيات الرياضية، يُعرف هذا المفهوم أحيانًا بـ الفضاء الشعاعي (Vector Space)، ولكن في جامعة الملك سعود بالرياض يُستخدم مصطلح “فضاءات المتجهات”. والمقصود به: بيئة رياضية يمكن فيها تمثيل وتوزيع المتجهات وفقًا لمعانيها وعلاقاتها ببعضها البعض، بحيث تُقاس المسافات بينها لبيان مدى التشابه أو التباعد في الدلالة.
تخيل الأمر كأنه خريطة متعددة الأبعاد:
- كل نقطة في هذه الخريطة تمثل قطعة من المحتوى: مقالة، صورة، أو ملف صوتي.
- المقالات المتقاربة في المعنى توضع على مقربة من بعضها.
- أما المحتويات البعيدة موضوعياً، فتوضع في مناطق مختلفة من الخريطة.
على سبيل المثال:
- مقال عن “رؤية السعودية 2030”، وآخر عن “التحولات الاقتصادية في الخليج” سيكونان قريبين داخل فضاء المتجهات لأنهما يشتركان في الموضوع والرؤية.
- في المقابل، مقال عن “الفن الباروكي في أوروبا” سيكون في موقع مختلف تماماً، لبُعده عن المجال الدلالي للمقالين السابقين.
بهذا الشكل، تتيح المتجهات لقواعد البيانات القدرة على استيعاب التشابه المعنوي بين المحتويات، لا مجرد مطابقة الكلمات. وهذا ما يُمهّد الطريق لمحركات بحث أكثر ذكاء، وأنظمة توصية دقيقة، وتجربة مستخدم مبنية على الفهم لا الحفظ.
كيف تبحث قاعدة بيانات المتجهات عن التشابه؟
بعد أن عرفنا أن كل كيان (نص، صورة، مقطع صوتي…) يُحوَّل إلى متجه عددي يمثل معناه، نصل الآن إلى قلب عمل قواعد بيانات المتجهات: البحث عن التشابه في المعنى، وليس فقط التطابق في الشكل.
لكن ما المقصود “بالتشابه” هنا؟
ليس المقصود أن تتطابق الصور أو الكلمات حرفياً، بل أن تكون قريبة في المعنى أو المحتوى. وهذا ما يُعبّر عنه رياضيًا بـ المسافة بين المتجهات داخل فضاءات المتجهات. كلما كانت المسافة بين متجهين أقصر، دلّ ذلك على تقارب المعنى بين المحتويين اللذين يمثلانهما.
كيف تُقاس هذه المسافة؟
قواعد بيانات المتجهات تعتمد على أساليب رياضية لحساب “درجة القرب” بين المتجهات، ومن أشهرها:
- المسافة الإقليدية (Euclidean Distance):
وهي تقيس المسافة الهندسية الفعلية بين نقطتين في الفضاء. يمكن تشبيهها بخط مستقيم يصل بين نقطتين على خريطة. - تشابه جيب التمام (Cosine Similarity):
وهي تقيس الزاوية بين متجهين بدلاً من المسافة، وتركّز على الاتجاه أكثر من الحجم. تُستخدم بكثرة في تطبيقات النصوص، لأنها تُحدّد مدى تشابه المعنى حتى لو اختلف طول النصوص.
كلا الطريقتين تُستخدم لاكتشاف مدى “تشابه” المتجهات، وبناءً عليه تُعرض النتائج الأقرب أولًا، كما لو كنت تبحث عن “مقالات مشابهة” أو “صور قريبة في الأسلوب والمحتوى”.
ما الذي تفعله قاعدة البيانات عملياً؟
عند إرسال استعلام (مثلاً: “صور لغروب الشمس في الجبال”)، تقوم قاعدة بيانات المتجهات بما يلي:
- تمرير الاستعلام إلى نموذج تضمين، لتحويله إلى متجه رقمي يمثل معناه.
- مقارنة هذا المتجه مع الملايين من المتجهات المخزنة في قاعدة البيانات.
- حساب درجة القرب (التشابه) مع كل متجه في القاعدة، باستخدام إحدى طرق القياس.
- إرجاع العناصر الأقرب، مرتبة بحسب درجة التشابه.
هذا ما يُعرف بـ البحث الدلالي (Semantic Search)، لأنه لا يبحث عن كلمات مطابقة، بل عن معانٍ متقاربة.
كيف تُبنى هذه المتجهات؟ (مدخل إلى نماذج التضمين)
في الفقرة السابقة، رأينا كيف تعتمد قواعد بيانات المتجهات على المقارنة بين المتجهات لاكتشاف التشابه الدلالي. لكن بقي السؤال الأهم: من أين تأتي هذه المتجهات أصلاً؟ وكيف يمكن تحويل نص أو صورة أو مقطع صوتي إلى سلسلة أرقام تعبّر عن معناه؟
هنا يدخل دور ما يُعرف باسم نماذج التضمين (Embedding Models)، وهي نماذج ذكاء اصطناعي مدربة على كميات هائلة من البيانات، وظيفتها استخراج الخصائص الخفية من المحتوى وتحويلها إلى تمثيل عددي (متجه).
آلية العمل باختصار:
- البيانات الخام (نصوص، صور، أصوات…) تمر عبر طبقات متعددة من النموذج.
- كل طبقة في نموذج التضمين تحلّل جانباً معيناً من البيانات:
- في الصور: الطبقات الأولى قد تكتشف الحواف والألوان، بينما الطبقات الأعمق تتعرّف على الأشكال والأنماط.
- في النصوص: الطبقات الأولى تحلل الكلمات منفردة، أما الطبقات الأعمق فتفهم السياق والمعنى الضمني.
- بعد المرور عبر هذه الطبقات، يتم استخلاص متجه عالي الأبعاد يُعبّر عن المحتوى بدقة من الناحية الدلالية.
أمثلة على نماذج التضمين حسب نوع البيانات:
| نوع البيانات | نموذج التضمين (Embedding Model) | الوظيفة |
|---|---|---|
| النصوص | GloVe، BERT، OpenAI Embeddings | استخراج المعنى من الكلمات والسياق |
| الصور | CLIP، ResNet، ViT | تحويل العناصر البصرية إلى تمثيل رقمي |
| الصوتيات | Wav2Vec | فهم الإشارات الصوتية وتحويلها إلى متجهات مفهومة |
على سبيل المثال، نموذج مثل CLIP (من OpenAI) يستطيع تحويل صورة لمنظر طبيعي إلى متجه رقمي يحتوي على خصائص مثل: وجود الجبال، تشبع الألوان، عناصر الغروب… إلخ، دون الحاجة إلى توصيف يدوي.
هذه المتجهات الناتجة من نماذج التضمين يتم تخزينها لاحقًا في قاعدة بيانات المتجهات، لتُصبح جاهزة لعمليات البحث والمقارنة.
كيف تُفهرس وتُسترجع؟ (مفاهيم HNSW، IVF، ANN)
عندما تحتوي قاعدة بيانات المتجهات على آلاف أو ملايين المتجهات، يصبح من غير العملي إجراء مقارنة مباشرة بين متجه الاستعلام وكل المتجهات المخزنة. فمع ارتفاع عدد الأبعاد، تزداد العمليات الحسابية اللازمة، مما يؤدي إلى بطء كبير في الأداء.
لهذا السبب، تعتمد هذه القواعد على ما يُعرف بـ فهرسة المتجهات (Vector Indexing)، وهي تقنيات رياضية تهدف إلى تنظيم فضاءات المتجهات بطريقة تسمح بالاسترجاع السريع والدقيق نسبياً.
المفهوم الأساسي: البحث عن الجار الأقرب ANN
تعمل قواعد البيانات على إيجاد المتجهات الأقرب لمتجه الاستعلام. هذا لا يتم دائمًا بطريقة “دقيقة 100%”، بل غالباً ما يُستخدم أسلوب التقريب الذكي للحصول على نتائج سريعة وفعالة، وهو ما يسمى بـ:
📦 شرح توضيحي لعدد من المصطلحات الرياضية
Approximate Nearest Neighbor (ANN)
تعني حرفياً: “البحث عن الجار الأقرب التقريبي”.
وهو نهج رياضي يُستخدم لتقليص عدد المقارنات بين المتجهات، عبر إيجاد متجهات يُرجّح بقوة أنها الأقرب، دون الحاجة لمقارنة كل المتجهات المخزنة.
الميزة: سرعة كبيرة في الأداء.
التكلفة: تَنازل طفيف جدًا عن دقة المطابقة الكاملة، وهو تنازل مقبول في معظم التطبيقات الواقعية.
HNSW – العوالم الهرمية الصغيرة القابلة للتنقل فيها (Hierarchical Navigable Small World)
خوارزمية تعتمد على بناء شبكة متعددة الطبقات، تُرتّب فيها المتجهات بطريقة تُشبه “الروابط الاجتماعية” في الشبكات.
- المتجهات القريبة تُربط ببعضها البعض.
- المتجهات الأبعد تُربط عبر طبقات عليا لتسريع التنقل داخل الشبكة.
🔹 النتيجة: سرعة عالية جداً في الاسترجاع مع دقة ممتازة.
فهرسة مقلوبة (Inverted File Index – IVF)
هي طريقة فهرسة تعتمد على تقسيم فضاء المتجهات إلى مجموعات (Clusters)، ثم إنشاء فهرس يشير إلى المتجهات داخل كل مجموعة، مما يُقلل عدد المقارنات المطلوبة عند الاستعلام.
🔹 الهدف: تسريع البحث عبر تجاهل المساحات غير ذات صلة بالاستعلام.
أشهر خوارزميات فهرسة المتجهات:
| الخوارزمية | الاسم الكامل | الفكرة الرئيسية |
|---|---|---|
| HNSW | Hierarchical Navigable Small World | إنشاء رسم بياني متعدد الطبقات يربط المتجهات المتشابهة |
| IVF | Inverted File Index | تقسيم المتجهات إلى مجموعات (Clusters) والبحث في الأنسب منها فقط |
| PQ | Product Quantization | ضغط تمثيل المتجهات لتسريع عمليات المقارنة |
كل خوارزمية من هذه الخوارزميات تقدم استراتيجية مختلفة لتحقيق التوازن بين سرعة الاسترجاع ودقة النتائج. وسنتناولها في صناديق توضيحية لاحقة ضمن كل مثال تطبيقي.
لماذا يُفضّل هذا النوع من الفهرسة؟
لأن البحث الدقيق بين ملايين المتجهات يحتاج إلى وقت وموارد ضخمة.
أما الفهرسة الذكية باستخدام خوارزميات مثل ANN، فتسمح بالوصول إلى نتائج شبه دقيقة في جزء بسيط من الزمن، مما يجعلها مثالية لتطبيقات التوصية، البحث الدلالي، والتفاعل اللحظي مع المستخدم.
أشهر قواعد بيانات المتجهات
مع تنامي الحاجة إلى البحث الدلالي وتحليل البيانات غير المهيكلة، ظهرت عدة قواعد بيانات متخصصة في التعامل مع المتجهات. هذه القواعد لم تعد مجرّد أدوات تجريبية، بل أصبحت حجر الأساس في تطبيقات الذكاء الاصطناعي الحديثة، خصوصاً في البحث، التوصية، والتحليل السياقي العميق.
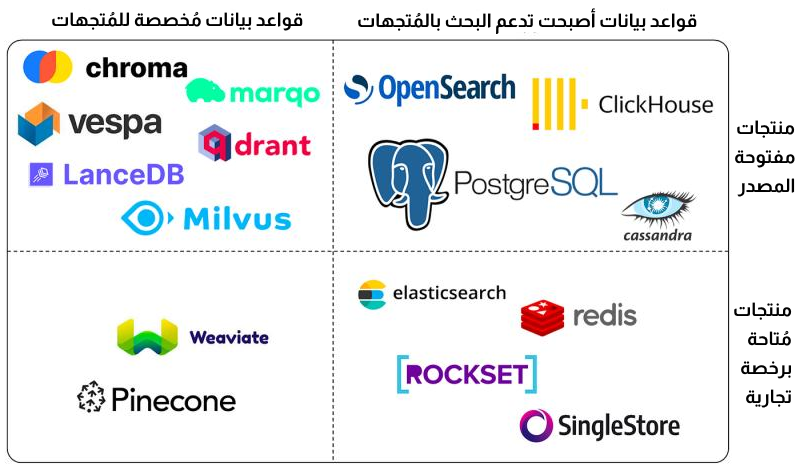
فيما يلي أبرز قواعد بيانات المتجهات، مع لمحة موجزة عن كل منها:
| الاسم | نبذة سريعة | مميزات بارزة |
|---|---|---|
| Pinecone | خدمة سحابية مُدارة بالكامل تركز على البحث الدلالي وتكامل الذكاء الاصطناعي | سريعة، جاهزة للإنتاج، تتكامل مع نماذج OpenAI بسهولة |
| FAISS | مكتبة مفتوحة المصدر من تطوير فيسبوك للبحث الفعّال في المتجهات | أداء عالٍ جدًا، تدعم GPU، لكن تحتاج إعداد يدوي |
| Weaviate | قاعدة متجهات مفتوحة المصدر، تدعم الفهم السياقي من المصدر | مبنية لتفهم النصوص مباشرة دون الحاجة إلى نموذج خارجي |
| Milvus | منصة قوية مفتوحة المصدر موجهة لمعالجة البيانات الضخمة من المتجهات | أداء قابل للتوسع، تدعم الفهرسة بأنواعها المختلفة |
| Qdrant | قاعدة متجهات مفتوحة المصدر مبنية بلغة Rust | توازن ممتاز بين الأداء والأمان، واجهات برمجة حديثة |
كيف أختار قاعدة البيانات المناسبة لي؟
يعتمد اختيارك على عدة عوامل، من أبرزها:
- هل تريد خدمة جاهزة وسحابية؟ إذن Pinecone خيار ممتاز.
- هل لديك فريق تقني قادر على إدارة مكتبات مفتوحة؟ فإن كل من FAISS أو Milvus مناسبين.
- هل تركز على فهم النصوص دون تدخل منك في النماذج؟ → Weaviate وQdrant سوف يتكفلان بعمل ذلك.
هل تدعم قواعد البيانات التقليدية التعامل مع المتجهات؟
مع تصاعد الاهتمام بقواعد بيانات المتجهات، بدأ كثير من المطورين وفرق التقنية يتساءلون:
هل علينا الاستغناء عن قواعد البيانات العلائقية التقليدية مثل Oracle أو PostgreSQL أو SQL Server؟ أم أنها أصبحت تدعم المتجهات أيضاً؟
الإجابة المختصرة:
بعض قواعد البيانات التقليدية بدأت فعلاً في دعم المتجهات، لكنها ليست قواعد متجهات بالكامل.
إليك المشهد الحالي:
| قاعدة البيانات | حالة الدعم | ملاحظات |
|---|---|---|
| PostgreSQL + pgvector | ✅ دعم جيد عبر إضافة خارجية | مكتبة pgvector تتيح تخزين المتجهات والبحث عنها باستخدام ANN |
| Oracle | ✅ دعم مدمج (Oracle AI Vector Search) | ضمن الإصدار 23c، دعم رسمي للبحث الدلالي بدمج الذكاء الاصطناعي |
| SQL Server | ⏳ في مرحلة تجريبية (Public Preview) | دعم أولي لتمثيل المتجهات والبحث التقريبي (2024) |
| Redis | ✅ دعم قوي عبر Redis Vector | أداء سريع جداً، مناسب لتطبيقات فورية، محدود في التعقيد البنيوي |
إذاً، هل يمكنني الاعتماد عليها بالكامل؟
ليس دائماً، وإليك مقترح يراه المختصون أنه عملي ومنطقي:
- إذا كان مشروعك صغيراً أو متوسطاً، وترغب بتجربة قدرات البحث الدلالي ضمن بيئة قواعد بيانات مألوفة بالنسبة لك (مثل PostgreSQL)، فقد تكون الإضافات التي الحقت مؤخراً قواعد البيانات كافية.
- أما إذا كان المشروع يعتمد بشكل جوهري على البحث في ملايين المتجهات، أو على تكامل عميق مع نماذج تضمين حديثة، فستحتاج إلى قاعدة بيانات متجهات متخصصة.
هل أحتاج فعلاً إلى قاعدة بيانات متجهات؟
قد تكون قرأت كل ما سبق وشعرت بالحماس، لكنك تتساءل:
هل أحتاج فعلياً إلى قاعدة بيانات متجهات؟ أم أن أدواتي الحالية تكفيني؟
الإجابة تتوقف على طبيعة بياناتك، والأسئلة التي تود أن تُجيب عنها.
ولأجل ذلك، دعنا نوضح الفرق بطريقة عملية.
مقارنة تطبيقية بين الحالتين:
| السيناريو | قاعدة تقليدية (SQL مثل PostgreSQL) | قاعدة متجهات |
|---|---|---|
| البحث عن منتجات سعرها أقل من 100 ريال | ✅ ممكن وسريع | ❌ ليس هدفها |
| البحث عن مقالات تحتوي على كلمة “تمويل” | ✅ ممكن | ✅ ممكن (لكن أقل كفاءة) |
| البحث عن مقالات تشبه في فكرتها مقالة معينة | ❌ غير ممكن فعليًا | ✅ حل مثالي |
| توصية بمحتوى مشابه لتفضيلات المستخدم | ❌ صعب ومحدود | ✅ مثالي |
| مطابقة صور بناءً على الأسلوب البصري | ❌ غير مدعوم | ✅ جوهري وهو الأنسب |
| البحث داخل تسجيلات صوتية بناءً على معناها | ❌ غير عملي | ✅ مدعوم (عبر نماذج تضمين صوتي) |
| تحليل مشاعر نصوص متعددة وتحديد الأكثر إيجابية | ✅ جزئيًا (مع أدوات مساعدة) | ✅ دقيق وذكي (باستخدام المتجهات) |
باختصار:
- إن كنت تتعامل مع بيانات مهيكلة (Structured Data) وتطرح استعلامات تقليدية، فأنت لا تحتاج إلى قواعد متجهات.
- أما إذا كانت بياناتك غير مهيكلة (مثل النصوص، الصور، المقاطع الصوتية)، وتريد استخراج معناها الضمني أو إيجاد تشابه في المحتوى والمعنى، فهنا تبرز الحاجة الواضحة لقواعد بيانات المتجهات.
الأسئلة الشائعة (FAQ)
1. هل تحل قواعد بيانات المتجهات محل قواعد البيانات التقليدية؟
لا، قواعد المتجهات لا تستبدل القواعد التقليدية، بل هي مكمل لها ضمن تصميم الحل التقني.
فهي مخصصة للتعامل مع البيانات غير المهيكلة والبحث الدلالي، بينما تبقى القواعد التقليدية الأفضل للعمليات المتعلقة بالجداول والعلاقات والمنطق التحليلي الصارم.
2. هل يمكن دمج قواعد المتجهات مع قواعدي الحالية؟
نعم.
يمكنك استخدام قواعد مثل Weaviate أو FAISS بجانب PostgreSQL مثلاً، حيث تعمل الأولى كمحرك بحث دلالي، والثانية كمخزن بيانات مهيكل.
هناك أيضاً حلول هجينة مثل pgvector أو Oracle AI Vector Search، التي تُدمج إمكانيات المتجهات داخل القواعد التقليدية مباشرة.
3. ما الفرق بين محركات البحث (Search Engines) وقواعد المتجهات؟
محركات البحث التقليدية (مثل Elasticsearch) تعتمد على المطابقة النصية (Keyword Matching)، وتُرتّب النتائج حسب التطابق أو الصيغة.
أما قواعد المتجهات، فتعتمد على فهم المعنى الكامن وراء النص أو الصورة، مما يتيح استرجاع النتائج حتى لو اختلفت الكلمات، ما يُعرف بالبحث الدلالي (Semantic Search).
4. ما علاقة هذه القواعد بتقنيات الذكاء الاصطناعي؟
إن علاقتها وثيقة جداً.
نموذج الذكاء الاصطناعي مثل ChatGPT لا “يعرف” الحقائق، بل يُولد إجابات بناءً على أنماط لغوية.
وعندما نُخزّن المعرفة كمتجهات (باستخدام قواعد المتجهات)، يمكن للنموذج أن يسترجع المعلومات بدقة، ثم يستخدمها للإجابة. هذا يُعرف باسم:
📦 صندوق توضيحي
التوليد المعزز بالاسترجاع (Retrieval-Augmented Generation – RAG)
تقنية تُدمج فيها قواعد المتجهات مع نماذج اللغة الكبيرة (LLMs)، بحيث تُستخدم قاعدة المتجهات لاسترجاع “شرائح المعرفة”، ثم تُمرر إلى النموذج لتوليد إجابة مبنية على تلك الشرائح.
5. هل من الصعب البدء بقواعد المتجهات؟
ليس بالضرورة.
- إن كنت تبحث عن حل جاهز وسهل البدء، فـ Pinecone أو Qdrant Cloud خيارات مثالية.
- وإن كنت تميل إلى المصادر المفتوحة وترغب ببناء حلول مخصصة، فـ Weaviate وMilvus خيارات قابلة للتوسع مع دعم واسع من المجتمع.
الخاتمة وزبدّة التدوينة: عصر جديد لفهم البيانات… لا مجرد تخزينها
قواعد بيانات المتجهات ليست مجرد ترقية تقنية، بل تحوّل جوهري في الطريقة التي نتفاعل بها مع المعلومات.
لقد انتقلنا من أنظمة تسأل: ما الكلمة التي استخدمها المستخدم؟
إلى أنظمة تسأل: ما الذي يعنيه؟ وما الذي يُشبهه؟ وما الذي قد يُفيد بناءً على ذلك؟
هذا التحول من المطابقة الحرفية إلى الفهم الدلالي (Semantic Understanding) لا يمكن أن يُنجز إلا من خلال فضاءات المتجهات، حيث يتم تمثيل المعنى والأفكار والعلاقات المعقدة بين الكيانات الرقمية داخل فضاء رياضي عالي الأبعاد فشكرا لعلماء الرياضيات والجبرّ الأفذاذ.
لقد رأينا في هذه التدوينة:
- كيف تعمل قواعد المتجهات من الداخل.
- كيف تُحوَّل النصوص والصور والأصوات إلى متجهات.
- كيف تُفهرس وتُسترجع هذه المتجهات بكفاءة عالية.
- ومتى يكون استخدام هذه القواعد ضرورة، لا رفاهية.
البيانات لم تعُد مجرد ما نملكه، بل كيف نفهمه ونجعل منه قراراً.
وقواعد بيانات المتجهات، هي بوابة هذا الفهم. فمع هذه التقنية أصبح فهم الآله للبيانات يأتي قبل فهرسة البيانات داخل قواعد البيانات

